 By Kazu Yamamoto
By Kazu YamamotoThis is the last article for the series of "Improving the performance of Warp". Readers are supposed to read the following articles:
- Improving the performance of Warp
- Sending header and body at once
- Caching file descriptors
- Composing HTTP response headers
- Avoiding system calls
- Measuring the performance of Warp
I will explain possible items to improve the performance of Warp.
Conduit
I have special cabal program which automatically specifies the
-fprof-auto (aka -auto-all) and -fprof-cafs (aka -caf-all) flags
to libraries to be installed.
So, I can take profile of all top level functions.
Unfortunately, GHC profile has a limitation:
right profiling is possible if
a program runs in foreground and it does not spawn child processes.
Suppose that N is the number of workers in the configuration file of Mighty. If N is larger than or equal to 2, Mighty creates N child processes and the parent process just works to deliver signals. However, if N is 1, Mighty does not creates one child process. The executed process itself works for HTTP. So, we can get the correct profile for Mighty if N is equal to 1.
Here is a profile of Mighty 2.8.2 against the httperf benchmark:
COST CENTRE MODULE %time %alloc
socketConnection Network.Wai.Handler.Warp.Run 11.8 28.4
>>=.\ Control.Monad.Trans.Resource 8.4 1.9
>>=.\.(...) Control.Monad.Trans.Resource 7.7 8.0
sendloop Network.Sendfile.Linux 6.7 0.2
== Data.CaseInsensitive 3.1 3.7
parseFirst Network.Wai.Handler.Warp.Request 2.8 3.4
sendMsgMore.\ Network.Sendfile.Linux 2.8 0.2
push.push' Network.Wai.Handler.Warp.Request 2.1 2.0
connectResume.go Data.Conduit.Internal 2.1 1.1
MAIN MAIN 1.6 0.7
>>= Data.Conduit.Internal 1.3 1.1
control Control.Monad.Trans.Control 1.3 2.0
||> Control.Exception.IOChoice.Lifted 1.2 1.0
+++.p Network.Wai.Application.Classic.Path 1.2 1.3
foldCase Data.CaseInsensitive 1.2 3.1
composeHeader Network.Wai.Handler.Warp.ResponseHeader 1.2 1.2My observations are:
- I think that
socketConnectionandsendloopis relating torecv()andsendfile(), respectively. Since these are IO system calls, it might be natural to consume much time. I will come back this issue later. - Conduit and ResourceT also consumes much time. Michael is now thinking how to avoid this overhead.
- I believe (==) and
foldCaseare used byData.List.lookupto look up HTTP headers. I think we can eliminatelookupcompletely if we have better WAI definition.
Better WAI definition
In the HTTP response composer of Warp, lookup is used to look up:
- Connection:
- Content-Length:
- Server:
These header fields are added to ResponseHeader in Response by WAI applications.
If Response has dedicated fields for them, we can directly obtain its value.
And if there is API to add these special fields and other fields,
we can calculate the total length of HTTP response header incrementally.
So, we can eliminate the current method to calculate the length by
traversing ResponseHeader.
Memory allocation
When receiving and sending packets, buffers are allocated.
Andreas suggested these memory allocations may be the current bottleneck.
GHC RTS uses pthread_mutex_lock to obtain a large object (larger than
409 bytes in 64 bit machines).
I tried to measure how much memory allocation for HTTP response header
consume time. I copied the create function of ByteString to Warp and
surrounded mallocByteString with Debug.Trace.traceEventIO.
Then I complied Mighty with it and took eventlog.
The result eventlog is illustrated as follows:
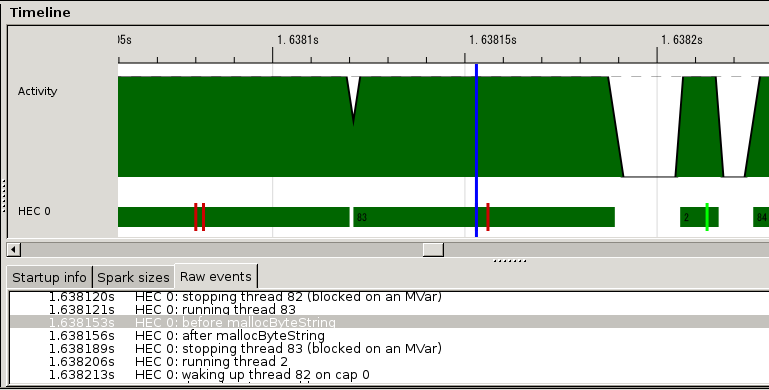
Brick red bars indicates the event created by traceEventIO.
The area surrounded by two bars is the time consumed by mallocByteString.
It is about 1/10 of an HTTP session.
I'm confident that the same thing happens when allocating receiving buffers.
Michael, Andreas and I are now discussing how to reduce this overhead.
Char8
ByteString is an array of Word8, non-negative 8bit digits. As many know, there are two sets of API for ByteString:
Data.ByteStringdirectly providesWord8APIData.ByteString.Char8provides API based onChar.
Since header field keys are case-insensitive,
we need to convert keys to lower (or upper) letters to identify.
To carry out this job,
Haskell programmers tends to use Data.ByteString.Char8
with toLower (or toUpper) of Data.Char.
Let's consider what kind of steps are necessary:
Haskell's Char is Unicode (UTF-32 or UCS-4).
The functions of Data.ByteString.Char8 are using the w2c and c2w functions
to convert Word8 to Char and Char to Word8, respectively.
Since Word8 is held in 32/64 bit registers,
w2c and c2w do nothing in assembler level.
The functions of Data.ByteString.Char8 themselves have no performance penalty.
However, toLower (or toUpper) of Data.Char targets the entire
space of Unicode. For our purpose, only 8bit part should be treated.
So, I implemented the word8 libraries which provides
toLower (and other functions) for both Word8 and 8bit portion of Char.
The criterion benchmark shows the following results:
Data.Char.toLower -- mean: 26.95289 us, lb 26.84163 us, ub 27.09798 us, ci 0.950
Data.Char8.toLower -- mean: 5.603473 us, lb 5.493357 us, ub 5.840760 us, ci 0.950So, the dedicated implementation is 5 times faster than
the Unicode implementation.
I'm planning to change Warp to use the word8 library.
Pessimistic recv()
The read()/recv() related functions of GHC are optimistic.
That is, they try to read data assuming that data is already available.
Since Handle/Socket are set non-blocking,
these functions will get the EAGAIN error if
data is not available.
In this case, these functions ask the IO manager to notify
when data becomes available.
This is accomplished by threadWaitRead.
Then, context is given to another thread.
When data become available,
the waiting thread is waken up by IO manager.
These functions obtain data finally.
When I took strace of Mighty, I saw many the EAGAIN errors caused by recv().
As a trial, I implement pessimistic recv().
That is, we call threadWaitRead before recv() to
ensure that data is available.
Let's compare two methods:
Optimistic recv():
- If data is available, only one
recv()is called. - Otherwise, the
epollrelated system calls andrecv()are issued as well as the firstrecv().
Pessimistic recv():
In any cases, the
epollrelated system calls andrecv()are issued.
I'm not sure which is better now.
By way of experiment, pessimistic recv() is enabled in Warp by default.
New thundering herd
Thundering herd is an old but new problem.
If a process/OS-thread pool is used to implement a network server,
the processes/OS-thread typically share a listening socket.
They call accept() on the socket.
When a connection is created, old Linux and FreeBSD
wakes up all of them. And only one can accept it and
the others sleeps again.
Since this causes many context switches,
we face performance problem.
This is called thundering herd.
Recent Linux and FreeBSD wakes up only one process/OS-thread.
So, this problem became a thing of the past.
Recent network servers tend to use the epoll/kqueue family.
If worker processes share a listen socket and they
manipulate accept connections through the epoll/kqueue family,
thundering herd appears again.
This is because
the semantics of the epoll/kqueue family is to notify
all processes/OS-threads.
I wrote code to demonstrate new thundering herd. If you are interested in, please check it out.
nginx and Mighty are victims of new thundering herd.
Andreas's parallel IO manager is free from new thundering herd.
In this architecture, only one IO manager accepts new connections
through the epoll family.
And other IO managers handle established connections.
Final remark
I would like to express gratitude to Michael for working on Warp together and correcting my language. I thank Andreas for useful suggestions to improve the performance of Warp.
Lastly, thank you all for reading my articles. I will come back here when there is significant progress.