 By Michael Snoyman
By Michael SnoymanKazu and I (mostly Kazu) have been working on a chapter on Warp for the upcoming "Performance of Open Source Applications," a semi-sequel to the book "Architecture of Open Source Applications." You've already seen some of the content on this blog in the past few months; below is our draft of the chapter. Feedback is highly welcome.
The actual content for this chapter lives on Github. Issues and pull requests are a very welcome way to receive comments.
Warp
Authors: Kazu Yamamoto and Michael Snoyman
Warp is a high-performance library of HTTP server side in Haskell,
a purely functional programming language.
Both Yesod, a web application framework, and mighty, an HTTP server,
are implemented over Warp.
According to our throughput benchmark,
mighty provides performance on a par with nginx.
This article will explain
the architecture of Warp and how we improved its performance.
Warp can run on many platforms,
including Linux, BSD variants, MacOS, and Windows.
To simplify our explanation, however, we will only talk about Linux
for the remainder of this article.
Network programming in Haskell
Some people believe that functional programming languages are slow or impractical. However, to the best of our knowledge, Haskell provides a nearly ideal approach for network programming. This is because the Glasgow Haskell Compiler (GHC), the flagship compiler for Haskell, provides lightweight and robust user threads (sometimes called green threads). In this section, we will briefly explain the history of server side network programming.
Native threads
Traditional servers use a technique called thread programming. In this architecture, each connection is handled by a single process or native thread- sometimes called an OS thread.
This architecture can be further segmented based on the mechanism used for creating the processes or native threads. When using a thread pool, multiple processes or native threads are created in advance. An example of this is the prefork mode in Apache. Otherwise, a process or native thread is spawned each time a connection is received. Fig (TBD:1.png) illustrates this.
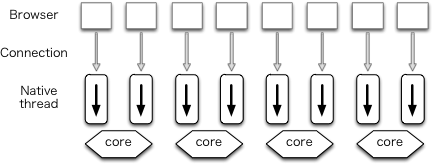
The advantage of this architecture is that it enables the developer to write clear code, since the code is not divided into event handlers. Also, because the kernel assigns processes or native threads to available cores, we can balance utilization of cores. Its disadvantage is that a large number of context switches between kernel and processes or native threads occur, resulting in performance degredation.
Event driven
Recently, it has been said that event-driven programming is required to implement high-performance servers. In this architecture multiple connections are handled by a single process (Fig (TBD:2.png)). Lighttpd is an example of a web server using this architecture.
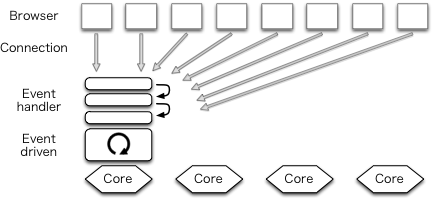
Since there is no need to switch processes, less context switches occur, and performance is thereby improved. This is its chief advantage. However, it has two shortcomings. The first is the fact that, since there is only a single process, only one core can be utilized. The second is that it requires asynchronous programming, so code is fragmented into event handlers. Asynchronous programming also prevents the conventional use of exception handling (although there are no exceptions in C).
1 process per core
Many have hit upon the idea of creating N event-driven processes to utilize N cores (Fig (TBD:3.png)). Each process is called a worker. A service port must be shared among workers. Using the prefork technique- not to be confused with Apache's prefork mode- port sharing can be achieved, after slight code modifications.
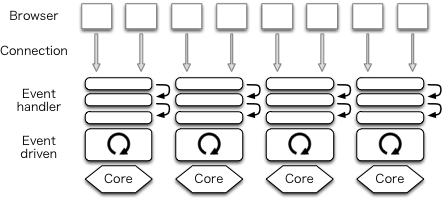
One web server that uses this architecture is nginx.
Node.js used the event-driven architecture in the past but
it also implemented this scheme recently.
The advantage of this architecture is
that it utilizes all cores and improves performance.
However, it does not resolve the issue of programs having poor clarity.
User threads
GHC's user threads can be used to solve the code clarity issue. They are implemented over an event-driven IO manager in GHC's runtime system. Standard libraries of Haskell use non-blocking system calls so that they can cooperate with the IO manager. GHC's user threads are lightweight; modern computers can run 100,000 user threads smoothly. They are robust; even asynchronous exceptions are caught (this feature is used timeout described in Section (TBD:Warp's architecture) and in Section (TBD:Timers for connections)).
Some languages and libraries provided user threads in the past, but they are not commonly used now because they are not lightweight or are not robust. But in Haskell, most computation is non-destructive. This means that almost all functions are thread-safe. GHC uses data allocation as a safe point to switch context of user threads. Because of functional programming style, new data are frequently created and it is known that such data allocation is regulaly enough for context switching.
Use of lightweight threads makes it possible to write clear code like traditional thread programming while keeping high-performance (Fig (TBD:4.png)).
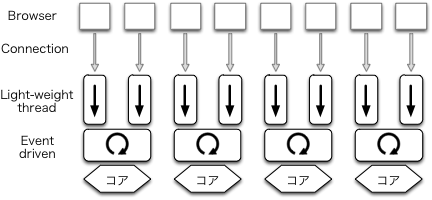
As of this writing, mighty uses the prefork technique to fork processes
to utilize cores and Warp does not have this functionality.
The Haskell community is now developing a parallel IO manager.
A Haskell program with the parallel IO manager is
executed as a single process and
multiple IO managers run as native threads to utilize cores.
Each user thread is executed on any one of the cores.
If and when this code is merged into GHC,
Warp itself will be able to use this architecture
without any modifications.
Warp's architecture
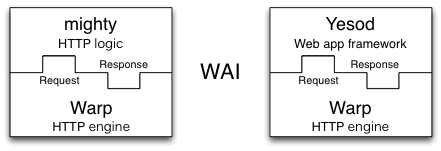
Warp is an HTTP engine for the Web Application Interface (WAI).
It runs WAI applications over HTTP.
As we described above, both Yesod and mighty are
examples of WAI applications, as illustrated in Fig (TBD:wai.png).
The type of WAI applications is as follows:
type Application = Request -> ResourceT IO ResponseIn Haskell, argument types of function are separated by right arrows and
the most right one is the type of return value.
So, we can interpret the definition
as a WAI application takes Request and returns Response.
After accepting a new HTTP connection, a dedicated user thread is spawned for the
connection.
It first receives an HTTP request from a client
and parses it to Request.
Then, Warp gives the Request to a WAI application and
receives a Response from it.
Finally, Warp builds an HTTP response based on the Response value
and sends it back to the client.
This is illustrated in Fig (TBD:warp.png).
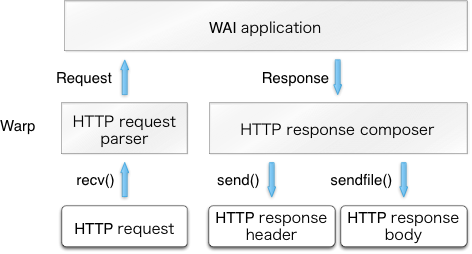
The user thread repeats this procedure as necessary and terminates itself when the connection is closed by the peer or and invalid request is received. It is also killed by the dedicated user thread for timeout if a significant amount of data is not received for a certain period.
Performance of Warp
Before we explain how to improve the performance of Warp,
we would like to show the results of our benchmark.
We measured throughput of mighty 2.8.2 (with Warp 1.3.4.1) and nginx 1.2.4.
Our benchmark environment is as follows:
- One "12 cores" machine (Intel Xeon E5645, two sockets, 6 cores per 1 CPU, two QPI between two CPUs)
- Linux version 3.2.0 (Ubuntu 12.04 LTS), which is running directly on the machine (i.e. without a hypervisor)
We tested several benchmark tools in the past and
our favorite one was httperf.
Since it uses select() and is just a single process program,
it reaches its performance limits when we try to measure HTTP servers on
multi-cores.
So, we switched to weighttp, which
is based on libev (the epoll family) and can use
multiple native threads.
We used weighttp as follows:
weighttp -n 100000 -c 1000 -t 3 -k http://127.0.0.1:8000/This means that 1,000 HTTP connections are established, with each connection sending 100 requests. 3 native threads are spawned to carry out these jobs.
For all requests, the same index.html file is returned.
We used nginx's index.html, whose size is 151 bytes.
As "127.0.0.1" suggests, we measured web servers locally.
We should have measured from a remote machine, but
we do not have a suitable environment at the moment.
Since Linux has many control parameters,
we need to configure the parameters carefully.
You can find a good introduction to
Linux parameter tuning in ApacheBench & HTTPerf.
We carefully configured both mighty and nginx as follows:
- Enabled file descriptor cache
- Disabled logging
- Disabled rate limitation
Since our machine has 12 cores and
weighttp uses three native threads,
we measured web servers from one worker to
eight workers (in our experience,
three native threads is enough to measure 8 workers).
Here is the result:
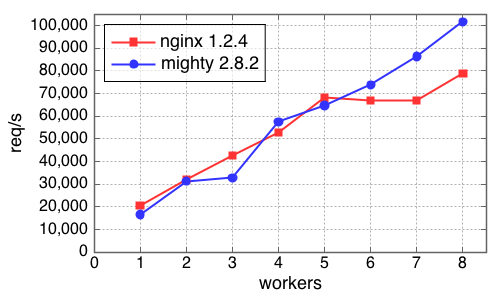
The x-axis is the number of workers and the y-axis gives throughput, measured in requests per second.
Key ideas
There are four key ideas to implement high-performance servers in Haskell:
- Issuing as few system calls as possible
- Specialization and avoiding re-calculation
- Avoiding locks
- Using proper data structures
Issuing as few system calls as possible
If a system call is issued,
CPU time is given to the kernel and all user threads stop.
So, we need to use as few system calls as possible.
For an HTTP session to get a static file,
Warp calls recv(), send() and sendfile() only (Fig (TBD:warp.png)).
open(), stat() and close() can be omitted
thanks to cache mechanism described in Section (TBD:Timers for file descriptors).
We can use the strace command to see what system calls are actually used.
When we observed the behavior of nginx with strace,
we noticed that it used accept4(), which we did not know about at the time.
Using Haskell's standard network library,
a listening socket is created with the non-blocking flag set.
When a new connection is accepted from the listening socket,
it is necessary to set the corresponding socket as non-blocking as well.
The network library implements this by calling fcntl() twice:
one is to get the current flags and the other is to set
the flags with the non-blocking flag ORed.
On Linux, the non-block flag of a connected socket
is always unset even if its listening socket is non-blocking.
accept4() is an extension version of accept() on Linux.
It can set the non-blocking flag when accepting.
So, if we use accept4(), we can avoid two unnecessary fcntl()s.
Our patch to use accept4() on Linux has been already merged to
the network library.
Specialization and avoiding re-calculation
GHC provides a profiling mechanism, but it has a limitation: correct profiling is only possible if a program runs in the foreground and does not spawn child processes. So, if we want to profile live activities of servers, we need to take special care for profiling.
mighty has this mechanism.
Suppose that N is the number of workers
in the configuration file of mighty.
If N is greater than or equal to 2, mighty creates N child processes
and the parent process just works to deliver signals.
However, if N is 1, mighty does not create any child process.
Instead, the executed process itself serves HTTP.
Also, mighty stays in its terminal if debug mode is on.
When we profiled mighty,
we were surprised that the standard function to format date string
consumed the majority of CPU time.
As many know, an HTTP server should return GMT date strings
in header fields such as Date:, Last-Modified:, etc:
Date: Mon, 01 Oct 2012 07:38:50 GMTSo, we implemented a special formatter to generate GMT date strings.
Comparing the standard function and our specialized function with
criterion, a standard benchmark library of Haskell,
ours are much faster.
But if an HTTP server accepts more than one request per second,
the server repeats the same formatting again and again.
So, we also implemented a cache mechanism for date strings.
We will also explain this topic in Section (TBD:Writing the Parser) and in Section (TBD:Composer for HTTP response header).
Avoiding locks
Unnecessary locks are evil for programming. Our code sometime uses unnecessary locks imperceptibly because, internally, the runtime systems or libraries use locks. To implement high-performance servers, we need to identify such locks and avoid them if possible. It is worth pointing out that locks will become much more critical under the parallel IO manager. We will talk about how to identify and avoid locks in Section (TBD:Timers for connections) and Section (TBD:Memory allocation).
Using proper data structures
Haskell's standard data structure for strings is String,
which is a linked list of Unicode characters.
Since list programming is the heart of functional programming,
String is convenient for many purposes.
But for high-performance servers, the list structure is too slow
and Unicode is overly complex since the HTTP protocol is based on byte streams.
Instead, we use ByteString to express strings (or buffers).
A ByteString is an array of bytes with meta data.
Thanks to this meta data,
splicing without copying is possible.
This is described in Section (TBD:Writing the Parser) in detail.
Other examples of proper data structures are
Builder and double IORef.
They are explained in Section (TBD:Composer for HTTP response header)
and Section (TBD:Timers for connections), respectively.
HTTP request parser
Besides the many issues involved with efficient concurrency and I/O in a multicore environment, Warp also needs to be certain that each core is performing its tasks efficiently. In that regard, the most relevant component is the HTTP request processing. The purpose is to take a stream of bytes coming from the incoming socket, parse out the request line and individual headers, and leave the request body to be processed by the application. It must take this information and produce a data structure which the application (whether a Yesod application, mighty, or something else) will use to form its response.
The request body itself presents some interesting challenges. Warp provides full support for pipelining and chunked request bodies. As a result, Warp must "dechunk" any chunked request bodies before passing them to the application. With pipelining, multiple requests can be transferred on a single connection. Therefore, Warp must ensure that the application does not consume too many bytes, as that would remove vital information from the next request. It must also be sure to discard any data remaining from the request body; otherwise, the remainder will be parsed as the beginning of the next request, causing either an invalid request or a misunderstood request.
As an example, consider the following theoretical request from a client:
POST /some/path HTTP/1.1
Transfer-Encoding: chunked
Content-Type: application/x-www-form-urlencoded
0008
message=
000a
helloworld
0000
GET / HTTP/1.1The HTTP parser must extract the /some/path pathname and the Content-Type header and pass these to the application.
When the application begins reading the request body, it must strip off the chunk headers (e.g., 0008 and 000a)
and instead provide the actual content, i.e. message=helloworld.
It must also ensure that no more bytes are consumed after the chunk terminator (0000)
so as not to interfere with the next pipelined request.
Writing the Parser
Haskell is known for its powerful parsing capabilities. It has traditional parser generators as well as combinator libraries, such as Parsec and Attoparsec. Parsec and Attoparsec's textual module work in a fully Unicode-aware manner. However, HTTP headers are guaranteed to be ASCII, so Unicode awareness is an overhead we need not incur.
Attoparsec also provides a binary interface for parsing, which would let us bypass the Unicode overhead. But as efficient as Attoparsec is, it still introduces an overhead relative to a hand-rolled parser. So for Warp, we have not used any parser libraries. Instead, we perform all parsing manually.
This gives rise to another question: how do we represent the actual binary data?
The answer is a ByteString, which is
essentially three pieces of data:
a pointer to some piece of memory,
the offset from the beginning of that memory to the data in question,
and the size of our data.
The offset information may seem redundant.
We could instead insist that our memory pointer point to the beginning of our data.
However, by including the offset, we enable data sharing.
Multiple ByteStrings can all point to the same chunk of memory and use different parts of it (a.k.a., splicing).
There is no concern of data corruption, since ByteStrings- like most Haskell data- are immutable.
When the final pointer to a piece of memory is no longer used, then the memory buffer is deallocated.
This combination is perfect for our use case. When a client sends a request over a socket, Warp will read the data in relatively large chunks (currently 4096 bytes). In most cases, this is large enough to encompass the entire request line and all request headers. Warp will then use its hand-rolled parser to break this large chunk into lines. This can be done quite efficiently since:
We need only scan the memory buffer for newline characters. The bytestring library provides such helper functions, which are implemented with lower-level C functions like
memchr. (It's actually a little more complicated than that due to multiline headers, but the same basic approach still applies.)There is no need to allocate extra memory buffers to hold the data. We just take splices from the original buffer. See figure (TBD:bytestring.png) for a demonstration of splicing individual components from a larger chunk of data. It's worth stressing this point: we actually end up with a situation which is more efficient than idiomatic C. In C, strings are null-terminated, so splicing requires allocating a new memory buffer, copying the data from the old buffer, and appending the null character.
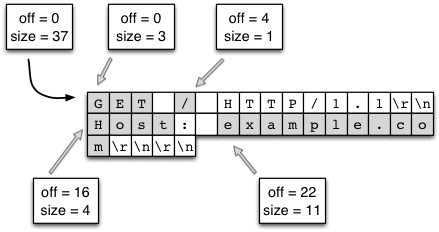
Once the buffer has been broken into lines, we perform a similar maneuver to turn the header lines into key/value pairs. For the request line, we parse the requested path fairly deeply. Suppose we have a request for:
GET /buenos/d%C3%ADas HTTP/1.1We need to perform the following steps:
Separate the request method, path, and version into individual pieces.
Tokenize the path along forward slashes, ending up with
["buenos", "d%C3%ADas"].Percent-decode the individual pieces, ending up with
["buenos", "d\195\173as"].UTF8-decode each piece, finally arriving at Unicode-aware text:
["buenos", "días"].
There are a few performance gains we have in this process:
As with newline checking, finding forward slashes is a very efficient operation.
We use an efficient lookup table for turning the Hex characters into numerical values. This code is a single memory lookup and involves no branching.
UTF8-decoding is a highly optimized operation in the text package. Likewise, the text package represents this data in an efficient, packed representation.
Due to Haskell's laziness, this calculation will be performed on demand. If the application in question does not need the textual version of the path, none of these steps will be performed.
The final piece of parsing we perform is dechunking. In many ways, dechunking is a simpler form of parsing. We parse a single Hex number, and then read the stated number of bytes. Those bytes are passed on verbatim- without any buffer copying- to the application.
Conduit
This article has mentioned a few times the concept of passing the request body to the application. It has also hinted at the issue of the application passing a response back to the server, and the server receiving data from and sending data to the socket. A final related point not yet discussed is middleware, which are components sitting between the server and application that somehow modify the request and/or response. The definition of a middleware is:
type Middleware = Application -> ApplicationThe intuition behind this is that a middleware will take some "internal" application, preprocess the request, pass it to the internal application to get a response, and then postprocess the response. For our purposes, a prime example would be a gzip middleware, which automatically compresses response bodies.
Historically, a common approach in the Haskell world for representing such streams of data has been lazy I/O.
Lazy I/O represents a stream of values as a single, pure data structure.
As more data is requested from this structure, I/O actions will be performed to grab the data from its source.
Lazy I/O provides a huge level of composability.
For example, we can write a function to compress a lazy ByteString,
and then apply it to an existing response body easily.
However, there are two major downsides to lazy I/O:
Non-deterministic resource finalization. If a reference to such a lazy structure is maintained, or if the structure isn't quickly evaluated to its completion, the finalization may be delayed for a long time (e.g., until a garbage collection sweep can ensure the data is no longer necessary). In many cases, this non-determinism is acceptable. In the case of a web server, file descriptors are a scarce resource, and therefore we need to ensure that they are finalized as soon as possible.
These pure structures present something of a lie. They are promising that there will be more bytes available, but in fact the I/O operations that will be performed to retrieve those bytes may fail. This can lead to exceptions being thrown where they are not anticipated.
We could drop down to a lower level and deal directly with file descriptors instead. However, this would hurt composability greatly. How would we write a general-purpose GZIP middleware? It also leaves open the question of buffering. Inherent in the request parsing described above, we have the need to store extra bytes for later steps. For example, if we grab a chunk of data which includes both request headers and some of the request body, the request body must be buffered and then provided to the application.
To address this, the WAI protocol- and therefore Warp- is built on top of the conduit package. This package provides an abstraction for streams of data. It keeps much of the compsability of lazy I/O, provides a buffering solution, and guarantees deterministic resource handling. Exceptions are also kept where they belong, in the parts of your code which deal with I/O.
Warp represents the incoming stream of bytes from the client as a Source,
and writes data to be sent to the client to a Sink.
The Application is provided a Source with the request body,
and provides a response as a Source as well.
Middlewares are able to intercept the Sources for the request and response bodies
and apply transformations to them.
Figure (TBD:middleware.png) demonstrates how a middleware fits between Warp and an application.
The composability of the conduit package makes this an easy and efficient operation.
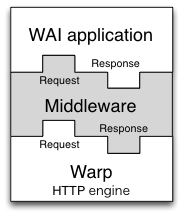
Conduit itself is a large topic, and therefore will not be covered in more depth. Suffice it to say for now that conduit's usage in Warp is a contributing factor to its high performance.
Slowloris protection
We have one final concern: the slowloris attack. This is a form of a Denial of Service (DOS) attack wherein each client sends very small amounts of information. By doing so, the client is able to maintain a higher number of connections on the same hardware/bandwidth. Since the web server has a constant overhead for each open connection regardless of bytes being transferred, this can be an effective attack. Therefore, Warp must detect when a connection is not sending enough data over the network and kill it.
We discuss the timeout manager in more detail below,
which is the true heart of slowloris protection.
When it comes to request processing,
our only requirement is to tease the timeout handler to let it know more data has been received from the client.
In Warp, this is all done at the conduit level.
As mentioned, the incoming data is represented as a Source. As part of that Source,
every time a new chunk of data is received, the timeout handler is teased.
Since teasing the handler is such a cheap operation (essentially just a memory write),
slowloris protection does not hinder the performance of individual connection handlers in a significant way.
HTTP response composer
This section describes the HTTP response composer of Warp.
A WAI Response has three constructors:
ResponseFile Status ResponseHeaders FilePath (Maybe FilePart)
ResponseBuilder Status ResponseHeaders Builder
ResponseSource Status ResponseHeaders (Source (ResourceT IO) (Flush Builder))ResponseFile is used to send a static file while
ResponseBuilder and ResponseSource are for sending
dynamic contents created in memory.
Each constructor includes both Status and ResponseHeaders.
ResponseHeaders is defined as a list of key/value header pairs.
Composer for HTTP response header
The old composer built HTTP response header with a Builder,
a rope-like data structure.
First, it converted Status and each element of ResponseHeaders
into a Builder. Each conversion runs in O(1).
Then, it concatenates them by repeatedly appending one Builder to another.
Thanks to the properties of Builder, each append operation also runs in O(1).
Lastly, it packs an HTTP response header
by copying data from Builder to a buffer in O(N).
In many cases, the performance of Builder is sufficient.
But we experienced that it is not fast enough for
high-performance servers.
To eliminate the overhead of Builder,
we implemented a special composer for HTTP response headers
by directly using memcpy(), a highly tuned byte copy function in C.
Composer for HTTP response body
For ResponseBuilder and ResponseSource,
the Builder values provided by the application are packed into a list of ByteString.
A composed header is prepended to the list and
send() is used to send the list in a fixed buffer.
For ResponseFile,
Warp uses send() and sendfile() to send
an HTTP response header and body, respectively.
Fig (TBD:warp.png) illustrates this case.
Again, open(), stat(), close() and other system calls can be committed
thanks to the cache mechanism described in Section (TBD:Timers for file descriptors).
The following subsection describe another performace tuning
in the case of ResponseFile.
Sending header and body together
When we measured the performance of Warp to send static files, we always did it with high concurrency. That is, we always made multiple connections at the same time. It gave us a good result. However, when we set the number of concurrency to 1, we found Warp to be really slow.
Observing the results of the tcpdump command,
we realized that this is because originally Warp used
the combination of writev() for header and sendfile() for body.
In this case, an HTTP header and body are sent in separate TCP packets (Fig (TBD:tcpdump.png)).
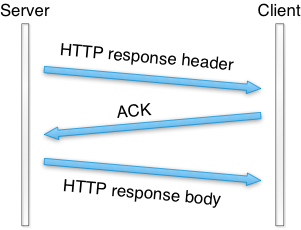
To send them in a single TCP packet (when possible),
new Warp switched from writev() to send().
It uses send() with the MSG_MORE flag to store a header
and sendfile() to send both the stored header and a file.
This made the throughput at least 100 times faster
according to our throughput benchmark.
Clean-up with timers
This section explain how to implement connection timeout and how to cache file descriptors.
Timers for connections
To prevent slowloris attacks,
communication with a client should be canceled
if the client does not send a significant amount of data
for a certain period.
Haskell provides a standard function called timeout
whose type is as follows:
Int -> IO a -> IO (Maybe a)The first argument is the duration of the timeout, in microseconds.
The second argument is an action which handles input/output (IO).
This function returns a value of Maybe a in the IO context.
Maybe is defined as follows:
data Maybe a = Nothing | Just aNothing indicates an error (without reason information) and
Just encloses a successful value a.
So, timeout returns Nothing
if an action is not completed in a specified time.
Otherwise, a successful value is returned wrapped with Just.
timeout eloquently shows how great Haskell's composability is.
Unfortunately,
timeout spawns a user thread to handle timeout.
To implement high-performance servers,
we need to avoid the creation of a user thread for timeout
for each connection.
So, we implemented a timeout system which uses only
one user thread, called the timeout manager, to handle the timeouts of all connections.
Its heart is the following two points:
- Double
IORefs - Safe swap and merge algorithm
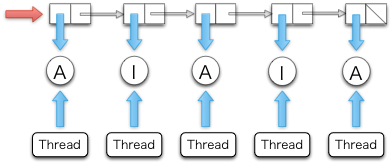
Suppose that status of connections is described as Active and Inactive.
To clean up inactive connections,
the timeout manager repeatedly inspects the status of each connection.
If status is Active, the timeout manager turns it to Inactive.
If Inactive, the timeout manager kills its associated user thread.
Each status is referred to by an IORef.
IORef is a reference whose value can be destructively updated.
To update status through this IORef,
atomicity is not necessary because status is just overwritten.
In addition to the timeout manager,
each user thread repeatedly turns its status to Active through its own IORef as its connection actively continues.
The timeout manager uses a list of the IORef to these statuses.
A user thread spawned for a new connection
tries to prepend its new IORef for an Active status to the list.
So, the list is a critical section and we need atomicity to keep
the list consistent.
A standard way to keep consistency in Haskell is MVar.
But MVar is slow,
since each MVar is protected with a home-brewed spin lock.
Instead, we used another IORef to refer the list and atomicModifyIORef
to manipulate it.
atomicModifyIORef is a function to atomically update IORef's values.
It is fast since it is implemented via CAS (Compare-and-Swap),
which is much faster than spin locks.
The following is the outline of the safe swap and merge algorithm:
do xs <- atomicModifyIORef ref (\ys -> ([], ys)) -- swap with an empty list, []
xs' <- manipulates_status xs
atomicModifyIORef ref (\ys -> (merge xs' ys, ()))The timeout manager atomically swaps the list with an empty list.
Then it manipulates the list by turning status and/or removing
unnecessary status for killed user threads.
During this process, new connections may be created and
their status are inserted via atomicModifyIORef by
their corresponding user threads.
Then, the timeout manager atomically merges
the pruned list and the new list.
Timers for file descriptors
Let's consider the case where Warp sends the entire file by sendfile().
Unfortunately, we need to call stat()
to know the size of the file
because sendfile() on Linux requires the caller
to specify how many bytes to be sent
(sendfile() on FreeBSD/MacOS has a magic number 0
which indicates the end of file).
If WAI applications know the file size,
Warp can avoid stat().
It is easy for WAI applications to cache file information
such as size and modification time.
If cache timeout is fast enough (say 10 seconds),
the risk of cache inconsistency problem is not serious.
And because we can safely clean up the cache,
we don't have to worry about leakage.
Since sendfile() requires a file descriptor,
the naive sequence to send a file is
open(), sendfile() repeatedly if necessary, and close().
In this subsection, we consider how to cache file descriptors
to avoid open() and close().
Caching file descriptors should work as follows:
if a client requests that a file be sent,
a file descriptor is opened by open().
And if another client requests the same file shortly thereafter,
the previously opened file descriptor is reused.
At a later time, the file descriptor is closed by close()
if no user thread uses it.
A typical tactic for this case is reference counting. But we were not sure that we could implement a robust mechanism for a reference counter. What happens if a user thread is killed for unexpected reasons? If we fail to decrement its reference counter, the file descriptor leaks. We noticed that the scheme of connection timeout is safe to reuse as a cache mechanism for file descriptors because it does not use reference counters. However, we cannot simply reuse the timeout manager for serveral reasons.
Each user thread has its own status. So, status is not shared.
But we would like to cache file descriptors to avoid open() and
close() by sharing.
So, we need to search for a file descriptor for a requested file
from cached ones.
Since this look-up should be fast, we should not use a list.
Also,
because requests are received concurrently,
two or more file descriptors for the same file may be opened.
So, we need to store multiple file descriptors for a single file name.
This is technically called a multimap.
We implemented a multimap whose look-up is O(log N) and pruning is O(N) with red-black trees whose node contains a non-empty list. Since a red-black tree is a binary search tree, look-up is O(log N) where N is the number of nodes. Also, we can translate it into an ordered list in O(log N). In our implementation, pruning nodes which contain a file descriptor to be closed is also done during this step. We adopted an algorithm to convert an ordered list to a red-black tree in O(N).
Future work
We have several ideas for improvement of Warp in the future, but we will explain two here.
Memory allocation
When receiving and sending packets, buffers are allocated.
We think that these memory allocations may be the current bottleneck.
GHC runtime system uses pthread_mutex_lock
to obtain a large object (larger than 409 bytes in 64 bit machines).
We tried to measure how much memory allocation
for HTTP response header consume time.
For this purpose, GHC provides eventlog which
can records timestamps of each event.
We surrounded a memory allocation function
with the function to record a user event.
Then we complied mighty with it and took eventlog.
The result eventlog is illustrated as follows:
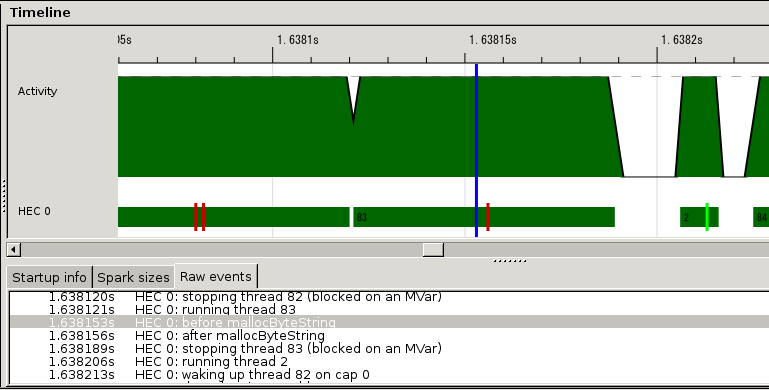
Brick red bars indicates the event created by us. So, the area surrounded by two bars is the time consumed by memory allocation. It is about 1/10 of an HTTP session. We are discussing how to implement memory allocation without locks.
New thundering herd
Thundering herd is an old but new problem.
Suppose that processes/native threads are pre-forked to share a listening socket.
They call accept() on the socket.
When a connection is created, old Linux and FreeBSD
wakes up all of them.
And only one can accept it and the others sleep again.
Since this causes many context switches,
we face a performance problem.
This is called thundering herd.
Recent Linux and FreeBSD wakes up only one process/native thread.
So, this problem became a thing of the past.
Recent network servers tend to use the epoll family.
If workers share a listening socket and
they manipulate accept connections through the epoll family,
thundering herd appears again.
This is because
the semantics of the epoll family is to notify
all processes/native threads.
nginx and mighty are victims of this new thundering herd.
The parallel IO manager is free from the new thundering herd problem.
In this architecture,
only one IO manager accepts new connections through the epoll family.
And other IO managers handle established connections.
Conclusion
Warp is a versatile web server library, providing efficient HTTP communication for a wide range of use cases. In order to achieve its high performance, optimizations have been performed at many levels, including network communications, thread management, and request parsing.
Haskell has proven to be an amazing language for writing such a codebase. Features like immutability by default make it easier to write thread-safe code and avoid extra buffer copying. The multi-threaded runtime drastically simplifies the process of writing event-driven code. And GHC's powerful optimizations mean that in many cases, we can write high-level code and still reap the benefits of high performance. Yet with all of this performance, our codebase is still relatively tiny (under 1300 SLOC at time of writing). If you are looking to write maintainable, efficient, concurrent code, Haskell should be a strong consideration.