 By Kazu Yamamoto
By Kazu YamamotoImproving the performance of Warp again
As you may remember, I improved the performance of Warp in 2012 and wrote some blog articles on this web site. Based on these articles, Michael and I wrote an article "Warp" for POSA (Performance of Open Source Applications).
After working with Andreas last year, I came up with some new ideas to yet again improve Warp's performance, and have implemented them in Warp 2.0. In this article, I will explain these new techniques. If you have not read the POSA article, I recommend to give a look at it beforehand.
Here are the high level ideas to be covered:
- Better thread scheduling
- Buffer allocation to receive HTTP requests
- Buffer allocation to send HTTP responses
- HTTP request parser
witty
When I was testing multicore IO manager with Mighty (on Warp), I noticed bottlenecks of network programs complied by GHC. To show such bottlenecks actually exist, I wrote a server program called witty based on Andreas's "SimpleServer".
"witty" provides seven command line options to switch standard methods to alternatives. My experiment with "witty" disclosed the following bottlenecks:
- Thread scheduling (the "-y" option)
Network.Socket.ByteString.recv(the "-r" option)
Better thread scheduling
GHC's I/O functions are optimistic.
For instance, recv tries to read incoming data immediately.
If there is data available, recv succeeds.
Otherwise, EAGAIN is returned.
In this case, recv asks the IO manager to notify it when data is available.
If a network server repeats receive/send actions,
recv just after send will usually fail because
there is a time lag for the next request from the client.
Thus the IO manager is often required to do notification work.
Here is a log of "strace":
recvfrom(13, ) -- Haskell thread A
sendto(13, ) -- Haskell thread A
recvfrom(13, ) = -1 EAGAIN -- Haskell thread A
epoll_ctl(3, ) -- Haskell thread A (a job for the IO manager)
recvfrom(14, ) -- Haskell thread B
sendto(14, ) -- Haskell thread B
recvfrom(14, ) = -1 EAGAIN -- Haskell thread B
epoll_ctl(3, ) -- Haskell thread B (a job for the IO manager)To achieve better scheduling, we need to call yield after send.
yield pushes its Haskell thread onto the end of thread queue.
In the meanwhile, other threads are able to work.
During the work of other threads, a new request message can arrive,
and therefore the next call to recv will succeed.
With the yield hack, a log of "strace" becames as follows:
recvfrom(13, ) -- Haskell thread A
sendto(13, ) -- Haskell thread A
recvfrom(14, ) -- Haskell thread B
sendto(14, ) -- Haskell thread B
recvfrom(13, ) -- Haskell thread A
sendto(13, ) -- Haskell thread AIn other words, yield makes the IO manager work less frequently.
This magically improves throughput!
This means that even multicore IO manager still has unignorable overhead.
It uses MVar to notify data availability to Haskell threads.
Since MVar is a lock, it may be slow.
Or perhaps, allocation of the MVar is slow.
Unfortunately when I first added yield to Warp, no performance improvement were
gained. It seems to me that Monad stack (ResourceT) handcuffs the yield
hack. So, Michael removed ResourceT from WAI. This is why the type of
Application change from:
type Application = Request -> ResourceT IO Responseto:
type Application = Request -> IO ResponseThis change itself improved the performance and enables the yield hack resulting in drastic performance improvement of Warp at least on small numbers of cores.
Michael has added an explanation of the removal of ResourceT to the end of this post.
Buffer allocation to receive HTTP requests
Warp used Network.Socket.ByteString.recv to receive HTTP requests. It appeared that this function has significant overhead. Let's dig its definition deeply:
recv :: Socket -> Int -> IO ByteString
recv sock nbytes = createAndTrim nbytes $ recvInner sock nbytesAs you can see, recv calls createAndTrim to create ByteString. Its definition is:
createAndTrim :: Int -> (Ptr Word8 -> IO Int) -> IO ByteString
createAndTrim l f = do
fp <- mallocByteString l
withForeignPtr fp $ \p -> do
l' <- f p
if assert (l' <= l) $ l' >= l
then return $! PS fp 0 l
else create l' $ \p' -> memcpy p' p l'Suppose we specify 4,096 as a buffer size to recv. First a ByteString of 4,096 bytes is created by mallocByteString. If the size of a received request is not 4,096, another ByteString is created by create and memcpy. create also calls mallocByteString as follows:
create :: Int -> (Ptr Word8 -> IO ()) -> IO ByteString
create l f = do
fp <- mallocByteString l
withForeignPtr fp $ \p -> f p
return $! PS fp 0 lSo, let's understand what happens when mallocByteString is called. Its definition is as follows:
mallocByteString :: Int -> IO (ForeignPtr a)
mallocByteString = mallocPlainForeignPtrBytesGHC.GHC.ForeignPtr provides mallocPlainForeignPtrBytes:
mallocPlainForeignPtrBytes :: Int -> IO (ForeignPtr a)
mallocPlainForeignPtrBytes (I# size) = IO $ \s ->
case newPinnedByteArray# size s of { (# s', mbarr# #) ->
(# s', ForeignPtr (byteArrayContents# (unsafeCoerce# mbarr#))
(PlainPtr mbarr#) #)
}As you can see, mallocPlainForeignPtrBytes calls newPinnedByteArray# which allocates a pinned object. Pinned objects are not moved by GHC's copy GC. That's why they are called pinned.
Substance of newPinnedByteArray# is rts/PrimOps.cmm:stg_newPinnedByteArrayzh which calls allocatePinned. allocatePinned is implemented in C in the file of "rts/sm/Storage.c":
StgPtr
allocatePinned (Capability *cap, W_ n)
{
StgPtr p;
bdescr *bd;
// If the request is for a large object, then allocate()
// will give us a pinned object anyway.
if (n >= LARGE_OBJECT_THRESHOLD/sizeof(W_)) {
p = allocate(cap, n);
Bdescr(p)->flags |= BF_PINNED;
return p;
}
...allocatePinned calls allocate if "n >= LARGE_OBJECT_THRESHOLD/sizeof(W_)" is met. Here is a part of the definition of allocate:
StgPtr
allocate (Capability *cap, W_ n) {
...
ACQUIRE_SM_LOCK
bd = allocGroup(req_blocks);
dbl_link_onto(bd, &g0->large_objects);
g0->n_large_blocks += bd->blocks; // might be larger than req_blocks
g0->n_new_large_words += n;
RELEASE_SM_LOCK;
...So, allocate uses a global lock. To my calculation, LARGE_OBJECT_THRESHOLD/sizeof(W_) is:
- 3,276 bytes (819 words) on 32 bit machines
- 3,272 bytes (409 words) on 64 bit machines
Caution: the numbers above were changed according to a comment from Simon Marlow.
Since old Warp specified 4,096 to recv, a global lock is acquired for every HTTP request. If the size of an HTTP request is some between 3,272(3,276) and 4,095, another global lock is obtained.
To avoid contention, I modified Warp so that a buffer of 4,096 bytes is allocated by malloc() for every HTTP connection. Sophisticated malloc() implementations have arena to avoid global contention. Also, since we repeat malloc() and free() for the same size, we can take advantage of the free list in malloc().
The buffer is passed to the recv() system call. After an HTTP request is received, a ByteString is allocated by mallocByteString and data is copied by memcpy. This tuning also improved the throughput of Warp drastically.
Buffer allocation to send HTTP response
Michael and I noticed that the buffer for receiving can also be used for sending. Let's recall that Response has three constructors:
data Response
= ResponseFile H.Status H.ResponseHeaders FilePath (Maybe FilePart)
| ResponseBuilder H.Status H.ResponseHeaders Builder
| ResponseSource H.Status H.ResponseHeaders (forall b. WithSource IO (C.Flush Builder) b)We changed that the buffer is also used for ResponseBuilder and ResponseSource to avoid extra buffer allocations. (In the case of ResponseFile, the zero copy system call, sendfile(), ensures no extra buffer is allocated.)
HTTP request parser
At this stage, I took profiles of Mighty. Here is a result:
sendfileloop Network.Sendfile.Linux 7.5 0.0
parseRequestLine Network.Wai.Handler.Warp.RequestHeader 3.6 5.8
sendloop Network.Sendfile.Linux 3.6 0.0
serveConnection.recvSendLoop Network.Wai.Handler.Warp.Run 3.1 1.9
>>= Data.Conduit.Internal 2.9 3.9I persuaded my self that I/O functions are slow. But I could not be satisfied with the poor performance of the HTTP request parser. parseRequestLine was implemented by using the utility functions of ByteString. Since they have overhead, I re-wrote it with Ptr-related functions. After writing the low-level parser, the profiling became:
sendfileloop Network.Sendfile.Linux 8.3 0.0
sendResponse Network.Wai.Handler.Warp.Response 3.7 3.1
sendloop Network.Sendfile.Linux 3.2 0.0
>>= Data.Conduit.Internal 2.9 4.0
serveConnection.recvSendLoop Network.Wai.Handler.Warp.Run 2.6 2.0I was happy because parseRequestLine disappeared from here. One homework for me is to understand why sendfileloop is so slow. Probably I need to check if locks are used in sendfile(). If you have any ideas, please let me know.
Performance improvement
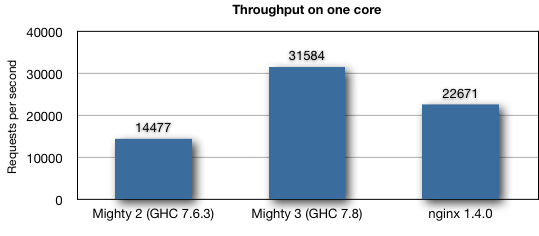
So, how fast Warp became actually? I show a chart to compare throughput among Mighty 2 complied by GHC 7.6.3, Mighty 3 compiled by coming GHC 7.8, and nginx 1.4.0. Note that only one core is used. I have two reasons for this: 1) since the change of data center of our company, I cannot use the environment described in the POSA article at this moment. So, I need to draw this chart based on my old memo. 2) nginx does not scale at all in my environment even if the deep sleep mode is disabled.
Anyway, here is the result measured by weighttp -n 100000 -c 1000 -k:
Removing ResourceT from WAI
Before we can understand how we removed ResourceT from WAI, we need to understand its purpose.
The goal is to allow an Application to acquire a scarce resource, such as a database connection.
But let's have a closer look at the three response constructors used in WAI (in the 1.4 series):
data Response
= ResponseFile H.Status H.ResponseHeaders FilePath (Maybe FilePart)
| ResponseBuilder H.Status H.ResponseHeaders Builder
| ResponseSource H.Status H.ResponseHeaders (C.Source (C.ResourceT IO) (C.Flush Builder))Both ResponseFile and ResponseBuilder return pure values which are unable to take
advantage of the ResourceT environment to allocate resources.
In other words, the only constructor which takes advantage of ResourceT is ResponseSource.
Our goal, therefore, was to limit the effect of resource allocation to just that constructor,
and even better to make the resource environment overhead optional in that case.
The first step is what Kazu already mentioned above: changing Application to live in IO instead of ResourceT IO.
We need to make the same change to the ResponseSource constructor.
But now we're left with a question: how would we acquire a resource inside a streaming response
in an exception safe manner?
Let's remember that an alternative to ResourceT is to use the bracket pattern.
And let's look at the structure of how a streaming response is processed in Warp.
(A similar process applies to CGI and other backends.)
- Parse the incoming request, generated a
Requestvalue. - Pass the
Requestvalue to the application, getting aResponsevalue. - Run the
Sourceprovided by the application to get individual chunks from theResponseand send them to the client.
In order to get exception safety, we need to account for three different issues:
Catch any exceptions thrown in the application itself while generating the
Response. This can already be handled by the application, since it simply lives in theIOmonad.Mask asynchronous exceptions between steps 2 and 3. This second point required a minor change to Warp to add async masking.
Allow the application to install an exception handler around step 3.
That third point is the bit that required a change in WAI.
The idea is to emulate the same kind of bracket API provided by functions like withFile.
Let's consider the signature for that function:
withFile :: FilePath -> IOMode -> (Handle -> IO a) -> IO a
-- or partially applied
withSomeFile "foo" ReadMode :: (Handle -> IO a) -> IO aIn our case, we don't want to get a Handle, but instead a Source of bytes.
Let's make a type signature or two to represent this idea:
type ByteSource = Source IO (Flush Builder)
type WithByteSource a = (ByteSource -> IO a) -> IO aAnd the resulting ResponseSource constructor is:
ResponseSource H.Status H.ResponseHeaders (forall b. WithByteSource b)To deal with the common case of installing a cleanup function, WAI provides the responseSourceBracket function.
At a higher level, Yesod is able to build on top of this to provide the same ResourceT functionality we had
previously, so that a Yesod user can simply use allocate and friends and get full exception safety.
Acknowledgment
Michael and I thank Joey Hess for getting Warp to work well on Windows and Gregory Collins for his discussions on performance.