 By Michael Snoyman
By Michael SnoymanAOSA Chapter on Yesod
The upcoming Architecture of Open Source Applications, volume 2 will include a chapter on Yesod. A big thanks to Amy Brown and Greg Wilson for including us. Here's a sneak peek for the impatient.
Introduction
Yesod is a web framework written in the Haskell programming language. While many popular web frameworks exploit the dynamic nature of their host languages, Yesod exploits the static nature of Haskell to produce safer, faster code.
Development began about two years ago, and has been going strong ever since. Yesod cut its teeth on real life projects, with all of its initial features borne out of an actual, real life need. At first, development was almost entirely a one-man show. After about a year of development, the community efforts kicked in, and Yesod has since blossomed into a thriving open-source project.
During the embryonic phase, when Yesod was incredibly ephemeral and ill-defined, it would have been counter-productive to try and get a team to work on it. By the time it stabilized enough to be useful to others, it was the right time to find out the downsides to some of the decisions that had been made. Since then, we have made major changes to the user-facing API to make it more useful, and are quickly solidifying a 1.0 release.
The question you may ask is: why another web framework? Let's instead redirect to a different question: why use Haskell? It seems that most of the world is happy with one of two styles of language:
- Statically typed languages, like Java, C# and C++. These languages provide speed and type safety, but are more cumbersome to program with.
- Dynamically typed languages, like Ruby and Python. These languages greatly increase productivity (at least in the short run), but run slowly and have very little support from the compiler to ensure correctness. (The solution to this last point is unit testing. We'll get to that later.)
This is a false dichotomy. There's no reason why statically typed languages need to be so clumsy. Haskell is able to capture a huge amount of the expressivity of Ruby and Python, while remaining a strongly typed language. In fact, Haskell's type system catches many more bugs than Java and its ilk. Null pointer exceptions are completely eliminated; immutable data structures simplify reasoning about your code and simplify parallel and concurrent programming.
So why Haskell? It is an efficient, developer-friendly language which provides many compile-time checks of program correctness.
The goal of Yesod is to extend Haskell's strengths into web development. Yesod strives to make your code as concise as possible. As much as possible, every line of your code is checked for correctness at compile time. Instead of requiring large libraries of unit tests to test basic properties, the compiler does it all for you. Under the surface, Yesod uses as many advanced performance techniques as we can muster to make your high-level code fly.
Compared to other frameworks
In general terms, Yesod is more similar than different when compared to the leading frameworks, such as Rails and Django. It generally follows the Model-View-Controller (MVC) paradigm, has a templating system that separates view from logic, provides an Object Relational Mapping (ORM) system, and has a front controller approach to routing.
The devil is in the details. Yesod strives to push as much error catching to the compile phase instead of runtime, and to automatically catch both bugs and security flaws through the type system. While Yesod tries to maintain a user-friendly, high-level API, it uses a number of newer techniques from the functional programming world to achieve high performance, and is not afraid to expose these internals to developers.
The main architectural challenge in Yesod is balancing these two seemingly conflicting goals. For example, there is nothing revolutionary about Yesod's approach to routing (called type-safe URLs). Historically, implementing such a solution was a tedious, error-prone process. Yesod's innovation is to use Template Haskell (a form of code generation) to automate the boilerplate required to bootstrap the process. Similarly, type-safe HTML has been around for a long while; Yesod tries to keep the developer-friendly aspect of common template languages while keeping the power of type safety.
Web Application Interface
A web application needs some way to communicate with a server. One possible approach is to bake the server directly into the framework, but doing so necessarily limits your options for deployment and leads to poor interfaces. Many languages have created standard interfaces to address this issue: Python has WSGI and Ruby has Rack. In Haskell, we have WAI.
WAI is not intended to be a high level interface. It has two specific goals: generality and performance. By staying general WAI has been able to support backends for everything from standalone servers to old school CGI and even works directly with Webkit to produce faux desktop applications. The performance side will introduce us to a number of the cool features of Haskell.

Datatypes
One of the biggest advantages of Haskell - and one of the things we make the most use of in Yesod - is strong static typing. Before we begin to write the code for how to solve something, we need to think about what the data will look like. WAI is a perfect example of this paradigm. The core concept we want to express is that of an application. An application's most basic expression is a function that takes a request and returns a response. In Haskell lingo:
type Application = Request -> Response
This just raises the question: what do Request and Response look like? A Request has a number of pieces of information, but the most basic are the requested path, query string, request headers, and request body. And a Response has just three components: a status code, response headers and response body.
How do we represent something like a query string? Haskell keeps a strict separation between binary and textual data. The former is represented by ByteString, the latter by Text. Both are highly optimized datatypes that provide a high level, safe API. In the case of query string we store the raw bytes transferred over the wire as a ByteString and the parsed, decoded values as Text.
Streaming
A ByteString represents a single memory buffer. If we were to naively use a plain ByteString for holding the entire request or response bodies, our applications could never scale to large requests or responses. Instead, we use a technique called enumerators, very similar in concept to generators in Python. Our application becomes a consumer of a stream of ByteStrings representing the incoming request body, and a producer of a separate stream for the response.
We now need to slightly revise our definition of an application. An application will take a request value, containing headers, query string, etc, and will consume a stream of ByteStrings, producing a Response. So the revised definition of an Application is:
type Application = Request -> Iteratee ByteString IO ResponseThe IO simply explains what types of side effects an application can perform. In the case of IO, it can perform any kind of interaction with the outside world, an obvious necessity for the vast majority of web applications.
Builder
The trick in our arsenal is how we produce our response buffers. We have a two competing desires here: minimizing system calls, and minimizing buffer copies. On the one hand, we want to minimize system calls for sending data over the socket. To do this we need to store outgoing data in a buffer. However, if we make this buffer too large, we will exhaust our memory and slow down the application's response time. On the other hand, we want to minimize the number of times data is copied between buffers, preferably copying just once from the source to destination buffer.
Haskell's solution is the builder. A builder is an instruction for how to fill a memory buffer, such as place the five bytes "hello" in the next open position. Instead of passing a stream of memory buffers to the server, a WAI application passes a stream of these instructions. The server takes the stream and uses it to fill up optimally sized memory buffers. As each buffer is filled, the server makes a system call to send the data over over the wire and then starts filling up the next buffer.
In theory, this kind of optimization could be performed in the application itself. However, by encoding this approach in the interface itself, we are able to simply prepend the response headers to the response body. The result is that, for small to medium sized responses, the entire response can be sent with a single system call and memory is copied only once.
Handlers
Now that we have an application, we need some way to run it. In WAI parlance, this is a handler. WAI has some basic, standard handlers, such as a standalone server (Warp, discussed below), FastCGI, SCGI and CGI. This spectrum allows WAI applications to be run on anything from dedicated servers down to shared hosting. But in addition to these, WAI has some more interesting backends:
- Webkit
- This backend embeds a Warp server and calls out to QtWebkit. By launching a server, followed by launching a new standalone browser window, we have faux desktop applications.
- Launch
- This is a slight variant on Webkit. Having to deploy the Qt and Webkit libraries can be a bit burdensome, so instead we just launch the user's default browser.
- Test
- Even testing counts as a handler. After all, testing is simply the act of running an application and inspecting the responses.
Most developers will likely use Warp. It is lightweight enough to be used for testing. It requires no config files, no folder hierarchy and no long-running, administrator owned process. It's a simple library that gets compiled into your application or run via the Haskell interpreter. On the flip side, Warp is an incredibly fast server, with protection from all kinds of attack vectors, such as slow loris and infinite headers. Warp can be the only web server you need, though it is also quite happy to sit behind a reverse HTTP proxy.
The PONG benchmark measures the requests per second of various servers for the 4-byte response body "PONG". In this graph, Yesod is measured as a framework on top of Warp. As can be seen, the Haskell servers (Warp, Happstack and Snap) lead the pack.
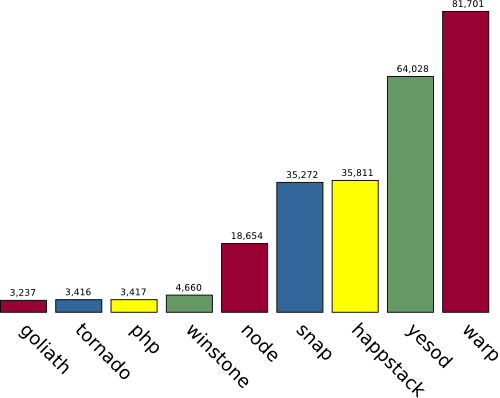
Most of the reasons for Warp's speed have already been spelled out in the overall description of WAI: enumerators, builders and packed datatypes. The last piece in the puzzle is from the Glasgow Haskell Compiler's (GHC's) multithreaded runtime. GHC, Haskell's flagship compiler, has light-weight green threads. Unlike system threads, it is possible to spin up thousands of these without serious performance hits. Therefore, in Warp, each connection is handled by its own green thread.
The next trick is asynchronous I/O. Any web server hoping to scale to tens of thousands of requests per second will need some type of asynchronous communication. In most languages, this involves complicated programming involving callbacks. GHC lets us cheat: we program as if we're using a synchronous API, and GHC automatically switches between different green threads waiting for activity.
Under the surface, GHC uses whatever system is provided by the host operating system, such as kqueue, epoll and select. This gives us all the performance of an event-based IO system, without worrying about cross-platform issues or writing in a callback-oriented way.
Middleware
In between handlers and applications, we have middlewares. Technically, a middleware
is an application transformer: it takes one application, and returns a new
one. This is defined as type Middleware = Application ->
Application. The best way to understand the purpose of a middleware is to look at some
common ones:
- gzip automatically compresses the response from an application.
- jsonp automatically converts JSON responses to JSON-P responses when the client provided a callback parameter.
- autohead will generate appropriate HEAD responses based on the GET response of an application.
- debug will print debug information to the console or a log on each request.
The theme here is to factor out common code from applications and let it be shared easily. Note that, based on the definition of a middleware, we can easily stack these things up. The general workflow of a middleware is:
- Take the request value and apply some modifications.
- Pass the modified request to the application and receive a response.
- Modify the response and return it to the handler.
wai-test
No amount of static typing will obviate the need for testing. We all know that automated testing is a necessity for any serious applications. wai-test is the recommended approach to testing a WAI application. Since requests and responses are simple datatypes, it is easy to mock up a fake request, pass it to an application, and test properties about the response. wai-test simply provides some convenience functions for testing common properties like the presence of a header or a status code.
Templates
In the typical Model-View-Controller (MVC) paradigm, one of the goals is to separate logic from the view. Part of this separation is achieved through the use of a template language. However, there are many different ways to approach this issue. At one end of the spectrum, for example, PHP/ASP/JSP will allow you to embed any arbitrary code within your template. At the other end, you have systems like StringTemplate and QuickSilver, which are passed some arguments and have no other way of interacting with the rest of the program.
Each system has its pros and cons. Having a more powerful template system can be a huge convenience. Need to show the contents of a database table? No problem, pull it in with the template. However, such an approach can quickly lead to convoluted code, interspersing database cursor updates with HTML generation. This can be commonly seen in a poorly written ASP project.
While weak template systems make for simple code, they also tend towards a lot of redundant work. You will often need to not only keep your original values in datatypes, but also create dictionaries of values to pass to the template. Maintaining such code is not easy, and usually there is no way for a compiler to help you out.
Yesod's family of template languages, the Shakespearean languages, strive for a middle ground. By leveraging Haskell's standard referential transparency, we can be assured that our templates produce no side effects. However, they still have full access to all the variables and functions available in your Haskell code. Also, since they are fully checked for both well-formedness, variable resolution and type safety at compile time, typos are much less likely to have you searching through your code trying to pin down a bug.
Types
One of the overarching themes in Yesod is proper use of types to make developers' lives easier. In Yesod templates, we have two main examples:
- All content embedded into a Hamlet template must have a type of
Html. As we'll see later, this forces us to properly escape dangerous HTML when necessary, while avoiding accidental double-escaping as well. - Instead of concatenating URLs directly in our template, we have datatypes- known as type-safe URLs- which represent the routes in our application.
As a real-life example, suppose that a user submits his/her name to an application via a form. This data would be represented with the Text datatype. Now we would like to display this variable, called name, in a page. The type system- at compile time- prevents it from being simply stuck into a Hamlet template, since it's not of type Html. Instead we must convert it somehow. For this, there are two conversion functions:
- toHtml will automatically escape any entities. So if a user submits the string
<script src="http://example.com/evil.js"></script>, the less than signs will automatically be converted to<. - preEscapedText, on the other hand, will leave the content precisely as it is now.
By default, Hamlet will use the toHtml function on any content you try to interpolate. Therefore, you only need to explicitly perform a conversion if you want to avoid escaping. This follows the dictum of erring on the side of caution.
name <- runInputPost $ ireq textField "name"
snippet <- readFile "mysnippet.html"
return [hamlet|
<p>Welcome #{name}, you are on my site!
<div .copyright>#{preEscapedText snippet}
|]
The first step in type-safe URLs is creating a datatype that represents all the routes in your site. Let us say you have a site for displaying Fibonacci numbers. The site will have a separate page for each number in the sequence, plus the homepage. This could be modeled with the Haskell datatype
data FibRoute = Home | Fib IntWe could then create a page like so:
<p>You are currently viewing number #{show index} in the sequence. Its value is #{fib index}.
<p>
<a href=@{Fib (index + 1)}>Next number
<p>
<a href=@{Home}>HomepageThen
all we need is some function to convert a type-safe URL into a string representation. In our
case, that could look something like
this:render :: FibRoute -> Text render Home = "/home" render (Fib i) = "/fib/" ++ show i
Fortunately, all of the boilerplate of defining and rendering type-safe URL datatypes is handled for the developer automatically by Yesod. We will cover that in more depth later.
The Other Languages
In addition to Hamlet, there are three other languages. Julius is used for Javascript. However, it's a simple pass-through language, just allowing for interpolation. In other words, barring accidental use of the interpolation syntax, any piece of Javascript could be dropped into Julius and be valid. For example, to test the performance of Julius, jQuery was run through the language without an issue.
The other two languages are alternate CSS syntaxes. Those familiar with the difference between Sass and Less will recognize this immediately: Cassius is whitespace delimited, while Lucius uses braces. Lucius is in fact a superset of CSS, meaning all valid CSS files are valid Lucius files. In addition to allowing text interpolation, there are some helper datatypes provided to model unit sizes and colors. Also, type-safe URLs work in these languages, making it convenient for specifying background images.
Aside from the type safety and compile-time checks mentioned above, having specialized languages for CSS and Javascript give us a few other advantages:
- For production, all the CSS and Javascript is compiled into the final executable, increasing performance (by avoiding file I/O) and simplifying deployment.
- By being based around the efficient builder construct described earlier, the templates can be rendered very quickly.
- There is built-in support for automatically including these in final webpages. We will get into this in more detail when describing widgets below.
Persistent
Most web applications will want to store information in a database. Traditionally, this has meant some kind of SQL database. In that regard, Yesod continues a long tradition, with PostgreSQL as our most commonly used backend. But as we have been seeing in recent years, SQL isn't always the answer to the persistence question. Therefore, Yesod was designed to work well with NoSQL databases as well, and ships with a MongoDB backend as a first-class citizen.
The result of this design decision is Persistent, Yesod's preferred storage option. There are really two guiding lights for Persistent: make it as backend agnostic as possible, and let user code be completely type-checked.
At the same time, we fully recognize that it is impossible to completely shield the user away from all details of the backend. Therefore, we provide two types of escape routes:
- Provide backend-specific functionality as necessary. For example, Persistent provides features for SQL joins and MongoDB lists and hashes. Proper portability warnings will apply, but if you want this functionality, it's there.
- Easy access to performing raw queries. We don't believe it's possible for any abstraction to cover every use case of the underlying library. If you just have to write a 5-table, correlated subquery in SQL, go right ahead.
Terminology
The most primitive datatype in Persistent is the PersistValue. This represents
any raw data that can appear within the database, such as a number, a date, or a string. Of
course, sometimes you'll have some more user-friendly datatypes you want to store, like HTML. For
that, we have the PersistField class. Internally, a
PersistField expresses itself to the database in terms of a
PersistValue.
All of this is very nice, but we will want to combine different fields together into a
larger picture. For this, we have a PersistEntity, which is basically a
collection of PersistFields. And finally, we have a PersistBackend that describes how to create, read, update and delete these
entities.
As a practical example, consider storing a person in a database. We want to store the
person's name, birthday, and a profile image (a PNG file). We create a new entity Person with three fields: a Text, a Day and a PNG. Each of those get stored in the
database using a different PersistValue constructor: PersistText, PersistDay and PersistByteString, respectively.
There is nothing surprising about the first two mappings, but the last one is interesting. There is no specific constructor for storing PNG content in a database, so instead we use a more generic type (a ByteString, which is just a sequence of bytes). We could use the same mechanism to store other types of arbitrary data.
How is all this represented in the database? Consider SQL as an example: the Person entity becomes a table with three columns (name, birthday, and
picture). Each field is stored as a different SQL type: Text becomes a
VARCHAR, Day becomes a Date and PNG becomes a BLOB (or
BYTEA).
The story for MongoDB is very similar. Person becomes its own
document, and its three fields each become a MongoDB field. There is
no need for data types or creation of a schema in MongoDB.
| Persistent | SQL | MongoDB |
| PersistEntity | Table | Document |
| PersistField | Column | Field |
| PersistValue | Column type | N/A |
Type Safety
Persistent handles all of the data marshaling concerns behind the scenes. As a user of
Persistent, you get to completely ignore the fact that a Text becomes a
VARCHAR. You are able to simply declare your datatypes and use
them.
Every interaction with Persistent is strongly typed. This prevents you from accidentally putting a number in the date fields; the compiler will not accept it. Entire classes of subtle bugs simply disappear at this point.
Nowhere is the power of strong typing more pronounced than in refactoring. Let's say you have been storing users' ages in the database, and you realize that you really wanted to store birthdays instead. You are able to make a single line change to your entities declaration file, hit compile, and automatically find every single line of code that needs to be updated.
In most dynamically-typed languages, and their web frameworks, the recommended approach to solving this issue is writing unit tests. If you have full test coverage, then running your tests will immediately reveal what code needs to be updated. This is all well and good, but it is a weaker solution than true types:
- It is all predicated on having full test coverage. This takes extra time, and worse, is boilerplate code that the compiler should be able to do for you.
- You might be a perfect developer who never forgets to write a test, but can you say the same for every person who will touch your codebase?
- Even 100% test coverage doesn't guarantee that you really have tested every case. All it's done is proven you've tested every line of code.
Cross-database Syntax
Creating an SQL schema that works for multiple SQL engines can be tricky enough. How do you create a schema that will also work with a non-SQL database like MongoDB?
Persistent allows you to define your entities in a high-level syntax, and will automatically create the SQL schema for you. In the case of MongoDB, we currently use a schema-less approach. This also allows Persistent to ensure that your Haskell datatypes match perfectly with the database's definitions.
Additionally, having all this information gives Persistent the ability to perform more advanced functions for you automatically, such as migrations.
Migrations
Persistent not only creates schema files as necessary, but will also automatically
apply database migrations if possible. Database modification is one of the less-developed pieces
of the SQL standard, and thus each engine has a different take on the process. As such, each
Persistent backend defines its own set of migration rules. In PostgreSQL, which has a rich set of
ALTER TABLE rules, we use those extensively. Since SQLite lacks much
of that functionality, we are reduced to creating temporary tables and copying rows. MongoDB's
schema-less approach means no migration support is required.
This feature is purposely limited to prevent any kind of data loss. It will not remove any columns automatically; instead, it will give you an error message, telling you the unsafe operations that are necessary in order to continue. You will then have the option to either manually run the SQL it provides you, or to change your data model to avoid the dangerous behavior.
Relations
Persistent is non-relational in nature, meaning it has no requirement for backends to support relations. However, in many use cases, we may want to use relations. In those cases, developers will have full access to them.
Assume we want to now store a list of skills with each user. If we were writing a MongoDB-specific app, we could go ahead and just store that list as a new field in the original Person entity. But that approach would not work in SQL. In SQL, we call this kind of relationship a one-to-many relationship.
The idea is to store a reference to the "one" entity (person) with each "many" entity (skill).
Then if we want to find all the skills a person has, we simply find all skills that reference
that person. For this reference, every entity has an ID. And as you might expect by now, these
IDs are completely type-safe. The datatype for a Person ID is PersonId. So to
add our new skill, we would just add the following to our entity definition:
Skill
person PersonId
name Text
description Text
UniqueSkill person name
This ID datatype concept comes up throughout Persistent and Yesod. You can dispatch based on an
ID. In such a case, Yesod will automatically marshal the textual representation of the ID to the
internal one, catching any parse errors along the way. These IDs are used for lookup and deletion
with the get and delete functions, and are returned by the
insertion and query functions insert and selectList.
Yesod
If we are looking through the typical Model-View-Controller (MVC) paradigm, Persistent is the model and Sheakespeare is the view. This would leave Yesod as the controller.
The most basic feature of Yesod is routing. It features a declarative syntax and type-safe dispatch. Layered on top of this, Yesod provides many other features: streaming content generation, widgets, i18n, static files, forms and authentication. But the core feature added by Yesod is really routing.
This layered approach makes it simpler for users to swap different components of the system. Some people are not interested in using Persistent. For them, nothing in the core system even mentions Persistent. Likewise, while commonly used features, not everyone needs authentication or static file serving.
On the other hand, many users will want to integrate all of these features. And doing so- while enabling all the optimizations available in Yesod- is not always straightforward. To simplify the process, Yesod provides a scaffolding tool as well that sets up a basic site with the most commonly used features.
Routes
Given that routing is really the main function of Yesod, let's start there. The routing syntax is very simple: a resource pattern, a name, and request methods. For example, a simple blog site might look like:
/ HomepageR GET /add-entry AddEntryR GET POST /entry/#EntryId EntryR GET
The first line defines the homepage. This says "I respond to the root path of the domain, I'm called HomepageR, and I answer GET requests."
The second line defines the add entry page. This time, we answer both GET and POST requests. You might be wondering why Yesod, as opposed to most frameworks, requires you to explicitly state your request methods. The reason is that Yesod tries to adhere to RESTful principles as much as possible, and a GET and POST request really have very different meanings. Not only do you state these two methods separately, but later you will define their handler functions separately.
The third line is a bit more interesting. After the second slash we have #EntryId. This defines a parameter of type EntryId. In the Persistent section, we already alluded to this feature: Yesod will now
automatically marshal the path component into the relevant ID value. Assuming an SQL backend
(Mongo is addressed later), if a user requests /entry/5, the handler
function will get called with an argument EntryId 5. But if the user
requests /entry/some-blog-post, Yesod will return a 404.
This is obviously possible in most other web frameworks as well. The approach taken
by Django, for instance, would use a regular expression for matching the routes, e.g. r"/entry/(\d+)". The Yesod approach, however, provides some advantages:
- Typing "EntryId" is much more semantic/developer-friendly than a regular expression.
- Regular expressions cannot express everything (or at least, can't do so
succinctly). We can use
/calendar/#Dayin Yesod; do you want to type a regex to match dates in your routes? - Yesod also automatically marshals the data for us. In our calendar case, our handler function
would receive a
Dayvalue. In the Django equivalent, the function would receive a piece of text which it would then have to marshal itself. This is tedious, repetitive and inefficient. - So far we've assumed that a database ID is just a string of digits. But what if it's more complicated? MongoDB uses GUIDs, for example. In Yesod, your #EntryId will still work, and the type system will instruct Yesod how to parse the route. In a regex system, you would have to go through all of your routes and change the (\d+) to whatever monstrosity of regex is needed to match.
Type-safe URLs
This approach to routing gives birth to one of Yesod's most powerful features: type-safe URLs. Instead of just splicing together pieces of text to refer to a route, every route in your application can be represented by a Haskell value. This immediately eliminates a large number of 404 not found errors: it is simply not possible to produce an invalid URL.
So how does this magic work? Each site has a route datatype, and each resource pattern gets its own constructor. In our previous example, we would get something that looks like:
data MySiteRoute = HomepageR | AddEntryR | EntryR EntryId
If you want to link to the homepage, you use HomepageR. To link to a specific
entry, you would use the EntryR constructor with an EntryId
parameter. For example, to create a new entry and redirect to it, you could write:
entryId <- insert (Entry "My Entry" "Some content") redirect RedirectTemporary (EntryR entryId)
Hamlet, Lucius and Julius all include built-in support for these type-safe URLs. Inside a Hamlet template, you can easily create a link to the add entry page:
<a href=@{AddEntryR}>Create a new entry.
The best part? Just like Persistent entities, the compiler will keep you honest. If you change any of your routes (e.g., you want to include the year and month in your entry routes), Yesod will force you to update every single reference throughout your codebase.
Handlers
Once you define your routes, you need to tell Yesod how you want to respond to
requests. This is where handler functions come into play. The setup is
simple; for each resource (e.g., HomepageR) and request method, create a function named
methodResourceR. For our previous example, we would need four functions: getHomepageR, getAddEntryR, postAddEntryR, and getEntryR.
All of the parameters collected from the route are passed in as arguments to the handler
function. getEntryR will take a first arugment of type EntryId, while all the
other functions will take no arguments.
The handler functions live in a Handler monad, which
provides a great deal of functionality, such as redirecting, accessing sessions, and running
database queries. For the last one, a typical way to start of the getEntryR function would be:
getEntryR entryId = do
entry <- runDB $ get404 entryId
This will run a database action that will get the entry associated with the given ID from the database. If there is no such entry, it will return a 404 response.
Each handler function will return some value, which must be an instance of
HasReps. This is another RESTful feature at play: instead of just returning
some HTML or some JSON, you can return a value that will return either one, depending on the HTTP
Accept request header. In other words, in Yesod, a resource is a specific piece of data, and it
can be returned in one of many representations.
Widgets
Assume you want to include a navbar on a few different pages of your site. This navbar will load up the five most recent blog posts (stored in your database), generate some HTML, and then need some CSS and Javascript to style and enhance.
Without a higher-level interface to tie these components together, this could be a pain to implement. You could add the CSS to the sitewide CSS file, but that's adding extra declarations you don't always need. Likewise with the Javascript, though a bit worse: having that extra Javascript might cause problems on a page it was not intended to live on. You will also be breaking modularity by having to generate the database results from multiple handler functions.
In Yesod, we have a very simple solution: widgets. A widget is a piece of code that ties together HTML, CSS and Javascript, allowing you to add content to both the <head> and <body>, and can run any arbitrary code that belongs in a handler. For example, to implement our navbar:
-- Get last five blog posts. The "lift" says to run this code like we're in the handler. entries <- lift $ runDB $ selectList [] [LimitTo 5, Desc EntryPosted] toWidget [hamlet| <ul .navbar> $forall entry <- entries <li>#{entryTitle entry} |] toWidget [lucius| .navbar { color: red } |] toWidget [julius|alert("Some special Javascript to play with my navbar");|]
But there is even more power at work here. When you produce a page in Yesod, the standard approach is to combine a number of widgets together into a single widget containing all your page content, and then apply defaultLayout. This function is defined per site, and applies the standard site layout.
There are two out-of-the-box approaches to handle where the CSS and Javascript goes:
- Concatenate them and place them into <style> and <script> tags, respectively, within your HTML.
- Place them in external files and refer to them with <link> and <script> tags, respectively.
In addition, your Javascript can be automatically minified. Option 2 is the preferred approach, since it allows a few extra optimizations:
- The files are created with names based on a hash of the contents. This means you can place cache values far in the future without worries of users receiving stale content.
- Your Javascript can be asynchronously loaded.
The second point requires a bit of elaboration. Widgets not only contain raw Javascript, they also contain a list of Javascript dependencies. For example, many sites will refer to the jQuery library and then add some Javascript that uses it. Yesod is able to automatically turn all of that into an asynchronous load via yepnope.js.
In other words, widgets allow you to create modular, composable code that will result in incredibly efficient serving of your static resources.
Subsites
Many websites share common pieces of functionality. Perhaps the two most common examples of this are serving static files and authentication. In Yesod, you can easily drop in this code using a subsite. All you need to do is add an extra line to your routes. For example, to add the static subsite, you would write:
/static StaticR Static getStatic
The first argument tells where in the site the subsite starts. The static subsite is
usually used at /static, but you could use whatever you want. StaticR is the name of the route;
this is also entirely up to you, but convention is to use StaticR. Static is the name of the
static subsite; this is one you do not have control over. getStatic is a
function that returns the settings for the static site, such as where the static files are
located.
Like all of your handlers, the subsite handlers also have access to the
defaultLayout function. This means that a well designed subsite will
automatically use your site skin without any extra intervention on your part.
Lessons Learned
Yesod has been a very rewarding project to work on. It has given me an opportunity to work on a large system with a diverse group of developers. One of the things that has truly shocked me is how different the end product has become versus what I had originally intended. I started off Yesod by creating a list of goals. Very few of the main features we currently tout in Yesod are in that list, and a good portion of that list is no longer something I plan to implement. The first lesson is:
You will have a better idea of the system you need after you start working on it. Do not tie yourself down to your initial ideas.
As this was my first major piece of Haskell code, I've learnt a lot about the language during Yesod's development. I'm sure others can relate to the feeling of "How did I ever write code like this?" Even though that initial code was not of the same caliber as the code we have in Yesod at this point, it was solid enough to kick-start the project. The second lesson is:
Don't be deterred due to supposed lack of mastery of the tools at hand. Write the best code you can, and keep improving it.
One of the most difficult steps in Yesod's development was moving from a single-person team- me- to collaborating with others. It started off simply with merging pull requests on Github, and eventually moved to having a number of core maintainers. I had established some of my own development patterns, which were nowhere explained or documented. As a result, contributors found it difficult to pull my latest unreleased changes and play around with them. This hindered others both from contributing and testing.
When Greg Weber came aboard as another lead on Yesod, he put in place a lot of the coding standards that were sorely lacking. To compound the problems, there were some inherent difficulties playing with the Haskell development toolchain, specifically dealing with Yesod's large number of packages. One of the goals of the entire Yesod team has since been to create standard scripts and tools to automate building. Many of these tools are making their way back into the general Haskell community. The final lesson is:
Consider early on how to make your project approachable for others.